
Is Audio The Ultimate No-Code Format?
A wild theory that ties Parappa the Rapper to Alexa and Siri

On Twitter, Jonathan Wegener asked about memorable voice UIs and early augmented audio experiences. As someone who used to be a little too good at Guitar Hero, I had some thoughts that intersected with process design and automation.


The short version: The popularity of rhythm games represents clear evidence that people can understand, learn, master, and build novel experiences on top of audio interfaces to a far greater extent than we understand today.
First, let’s review the modern history of rhythm games.

1996: Sony releases the first modern rhythm game, PaRappa the Rapper, on PlayStation in Japan and follows in the U.S. in 1997.
1997: Konami releases Beatmania in arcades and follows in 1998 with a console release.
1998: Konami releases Dance Dance Revolution in Japan and follows in Europe and North America in 1999.
2000-2004: DDR and its sequels absolutely crush it in arcades and consoles, but begin to decline after a flood of sequels. Meanwhile, a little company called Harmonix releases a couple of quirky rhythm games that catch the attention of RedOctane, a manufacturer of video game peripherals. RedOctane asks Harmonix to develop a game for a guitar-shaped controller.
2005: RedOctane publishes Guitar Hero. It's a smash hit, selling more than 1.5 million copies. Over the next 10+ years, games in the series will sell 25 million copies and earn more than $2B in revenue.
 - YouTube")
2006-2007: RedOctane is acquired by Activision and retains the Guitar Hero publishing rights. Harmonix is acquired by Viacom and goes on to develop Rock Band, which is released in late 2007.
2008: Music games represent 18% of the entire video game market. 18%!!!!! Even accounting for the higher purchase price associated with the peripherals, that's incredible.
2009: Both the Guitar Hero and Rock Band franchises release new games to disappointing sales.
2010: Activision closes RedOctane.
2011-2017: The major rhythm game franchises peter out and shift to harvesting profits via DLC. The last new Guitar Hero game comes out in 2015.
2018: Beat Games releases Beat Saber, a VR-based rhythm game. Although VR is still nascent, the game sells 2 million copies and 10 million DLC songs over the following two years and attracts a loyal following of players and song creators (and song tool creators).
2020: Harmonix returns with Fuser, a DJ simulator game with a campaign that is essentially an extended tutorial to learn how to use a failure-proof music mixing engine.
On the surface, this doesn't have anything to do with building new products. During the many dozens of hours I played Guitar Hero, I never once thought about it as a tool or even a multi-purpose toy. It was a game with pre-built levels and clearly-defined mechanics and goals. Who would build a platform on top of a music game?

But is a rhythm game with an audio-centric UI really that different from a voice UI like Alexa or Siri? Could you draw a line from the first tactile computers to DDR (and perhaps on to gesture controls in the future)?



The specifics of any one game are incidental. The resilience of the rhythm games category suggests that:
Non-musicians are exceedingly comfortable understanding, interacting with, and modifying naturalistic audio-based interfaces and even building new content at close to a professional level.
This market is massive, in part because it crosses demographic, linguistic, and cultural barriers with ease.
When Amazon released the first Echo with Alexa in 2014, I believe they were rediscovering the demand for this same capability, but with a different instrument — the infinitely nuanced, near-universal human voice.
And this, dear reader, is where we intersect with process design and automation.

Every time a new media format emerges, it's the same story.
First, the conventions of the previous dominant format are translated to the new format — just as early TV shows were a lot like radio shows and early digital advertising looked like print advertising. Over time, new creators iterate and experiment as they build the native vocabulary for the new format. That vocabulary is mature and systemized when it is repeatable by creators and recognizable by consumers and represents something that was simply not possible in the old format.
(That last bit is why I'm particularly interested in FUSER.)
Naturalistic voice UIs have been a staple of science fiction for decades, but they've only been widely available since 2014. Voice might be a the most natural interface in the world, but the vocabulary for building voice-controlled apps is still nascent. Today, you have to be comfortable deploying products directly to the cloud, so this is already out of reach for anyone who isn't a software developer. But let's put that aside for now and take a look at one of the best-known products for building conversational audio interfaces: Voiceflow.
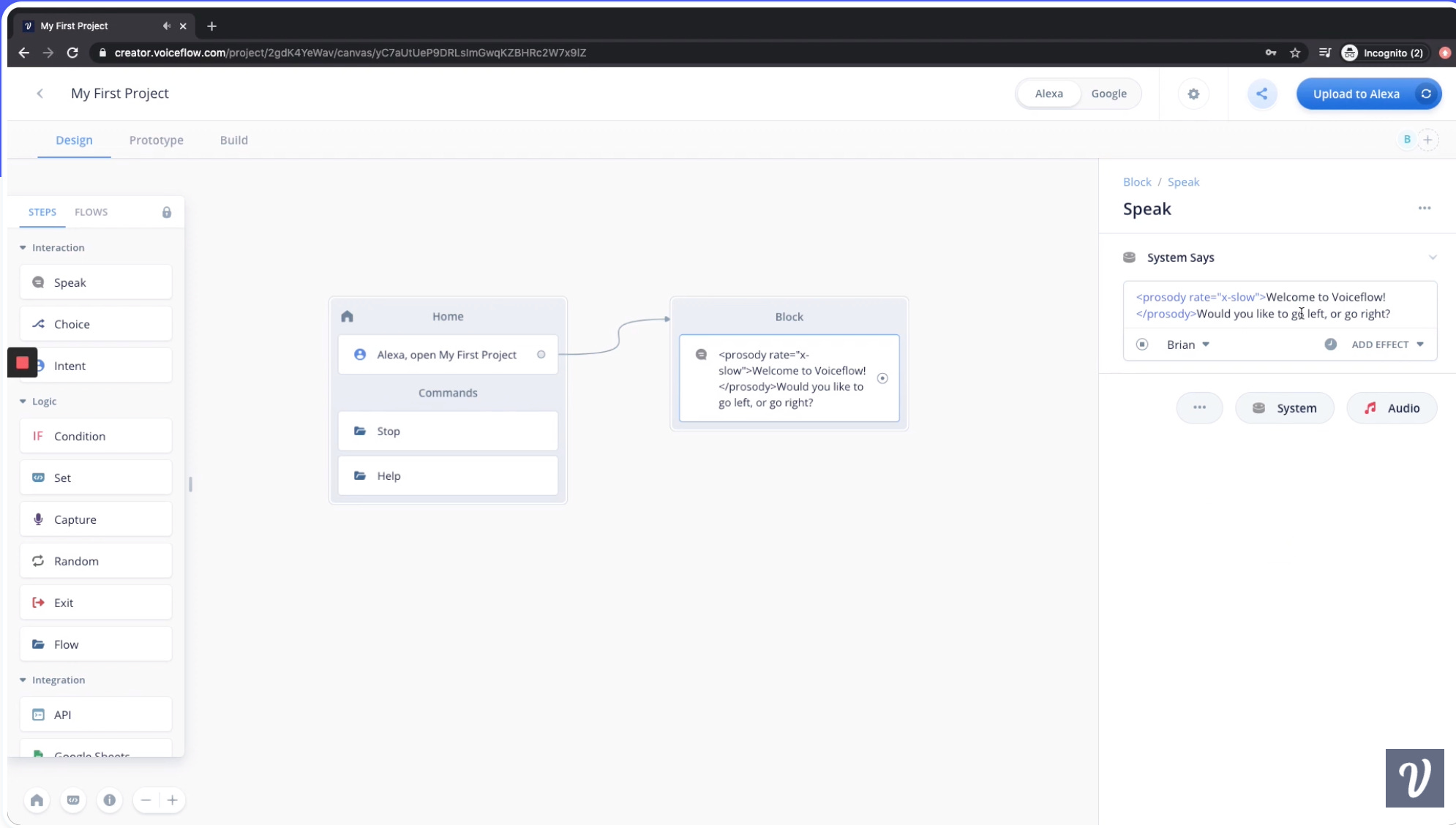
Go check out their homepage. Read the copy. Observe the animated product demos.
What do you notice about it all? The site is slick and the product images reveal an aesthetically-pleasing, legible interface. If you're a motivated professional, you can see how this can become a power tool pretty quickly.
But I'm more interested in hobbyists and amateurs who are willing and able to do just a little bit at first to customize their experience. And here's what I notice: In a vacuum, you're asking the user to pre-design a novel experience in a non-native format. Professionals can overcome this by doing manual UX research. Your average user cannot. And even if they could, they likely wouldn’t know where to start because process design does not start at the beginning. This space is not accessible to them.
I believe it would be accessible if users could build with less powerful tools but natively within the format.
Think about the first time you interacted with a voice assistant. You probably tested it or asked it to tell you a joke. You treated it like a toy — individual actions had no bearing outside of those closed-loop uses. But voice assistants become truly powerful not when they're feeding you information in a one-off manner but when they change the state of your digital or physical world. A single voice interaction is a toy that you play with, a voice-driven program or automation is part of a game you play, and, over time, anyone can combine multiple toys into games.
Here's where there's supposed to be a breakdown for voice: audio interfaces are constrained by what their users can recall. From this piece by Benedict Evans:
Given that you cannot answer [just] any question... does the user know what they can ask? I suspect that the ideal number of functions for a voice UI actually follows a U-shaped curve: one command is great and is ten probably OK, but 50 or 100 is terrible, because you still can't ask anything but can't remember what you can ask.
This remains a problem. Apple tightly restricts 3rd party development with Siri (and Siri is consequently useless). Google Assistant is somewhat better. Amazon is content to let virtually anyone upload an Alexa Skill, but that still restricts the domain of novel audio interfaces to developers and teams with the time and inclination to build them. And they'll still be building it in a visual format, which seems like the powerful and correct thing to do, but is not native to the format! And even with strong UX research, it's difficult to understand user intent at scale (or even sub-scale).
The premise of Automatter is that no-code and low-code tools with rigid constraints can support powerful, sophisticated use cases. The trick is in who is doing the building. Which brings me to another product with similar properties: LEGO.

It takes incredible skill and knowledge to design LEGO sets from scratch. It takes quite a bit of vision to build something of value from an assortment of LEGOs. But you can get incredibly far just by putting one block on another...

and then another...

and then another... until...

Here's my hypothesis: If you gave every Alexa user the ability to do a single custom automation entirely built through a native voice mechanic — no visual design tool, no cloud deployment, just you telling Alexa that when you ask for X, do X AND do Y — I think most people could handle it. You might not get a majority to add one, but if Amazon did a bit of customer education, they might get a significant chunk to add one.
And then one day, they might add another one. And then another on top of that. And then another. Until they've personalized an audio interface for their lives that would never have designed from scratch. If you asked them, they'd tell you they've never built an app or written a line of code in their lives.
And they might even be right about the latter.